

Scraping data from websites isn’t always easy. Between rate limits, blocked requests, JavaScript rendering, and unreliable proxies, even simple scraping tasks can get complicated fast.
Managing your own headless browsers, rotating IPs, and troubleshooting blocks can eat up hours of time — especially when all you want is consistent, structured data. It’s not just tedious; it slows down your workflow and adds unnecessary complexity to your stack.
ScrapingBee’s web scraping API is built to handle headless browsers, rotate proxies, and simplify how you extract data from modern web pages. This review covers what it offers, how it performs in real use, and how it compares to other scraping tools.
What Is ScrapingBee and How Does It Work?
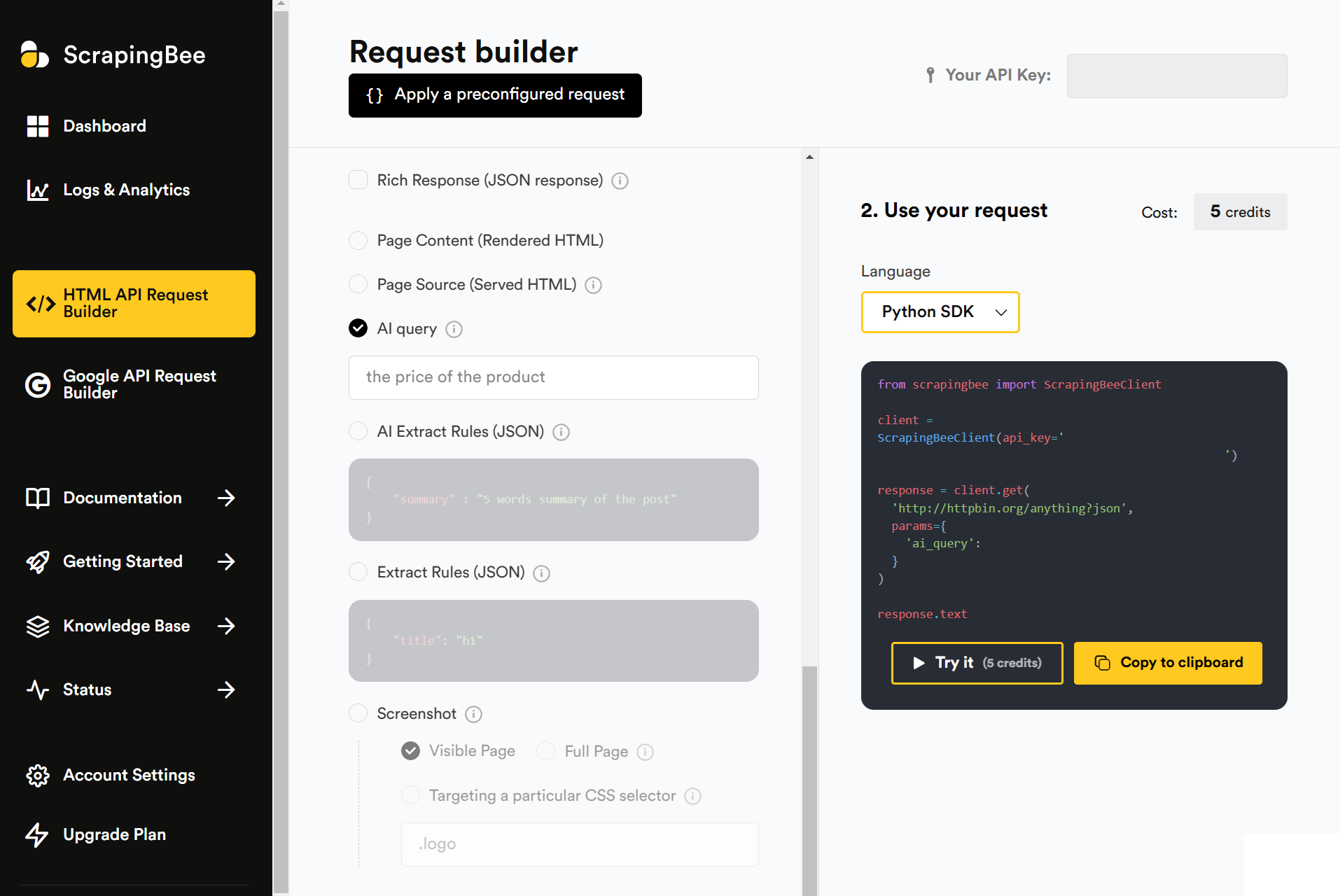
ScrapingBee is a web scraping API that handles headless browsers and rotates proxies automatically. It’s designed for developers who want to scrape web pages without dealing with browser infrastructure, rate limits, or proxy rotation.
You send a request with your API key, select options like JavaScript rendering, premium proxy, or custom headers, and receive either the raw HTML or structured JSON. ScrapingBee manages headless Chrome instances behind the scenes, so you don’t have to configure or maintain anything on your end.
ScrapingBee Features You Should Know About
ScrapingBee offers a range of features that simplify web scraping and help you avoid common blockers. Here’s what stands out.
JavaScript Rendering for Dynamic Websites
ScrapingBee uses real Chrome instances, so it works on sites that rely on JavaScript to load data. You can pass custom JS to click buttons, scroll, or wait for content.
Built-In Proxy Rotation and IP Geolocation
The API supports multiple proxy types:
- Rotating proxy (default)
- Premium proxy
- Stealth proxy
- Your own proxy
Each affects your credit usage. Rotating proxy with JS (default setting) costs 5 credits per request.
AI-Powered Web Scraping Without Selectors
You can describe what you want in plain language instead of writing CSS selectors. The AI figures out which parts of the page to extract and returns structured data. It adapts to layout changes and works well on listings or dynamic content.
JSON Data Extraction with CSS or XPath
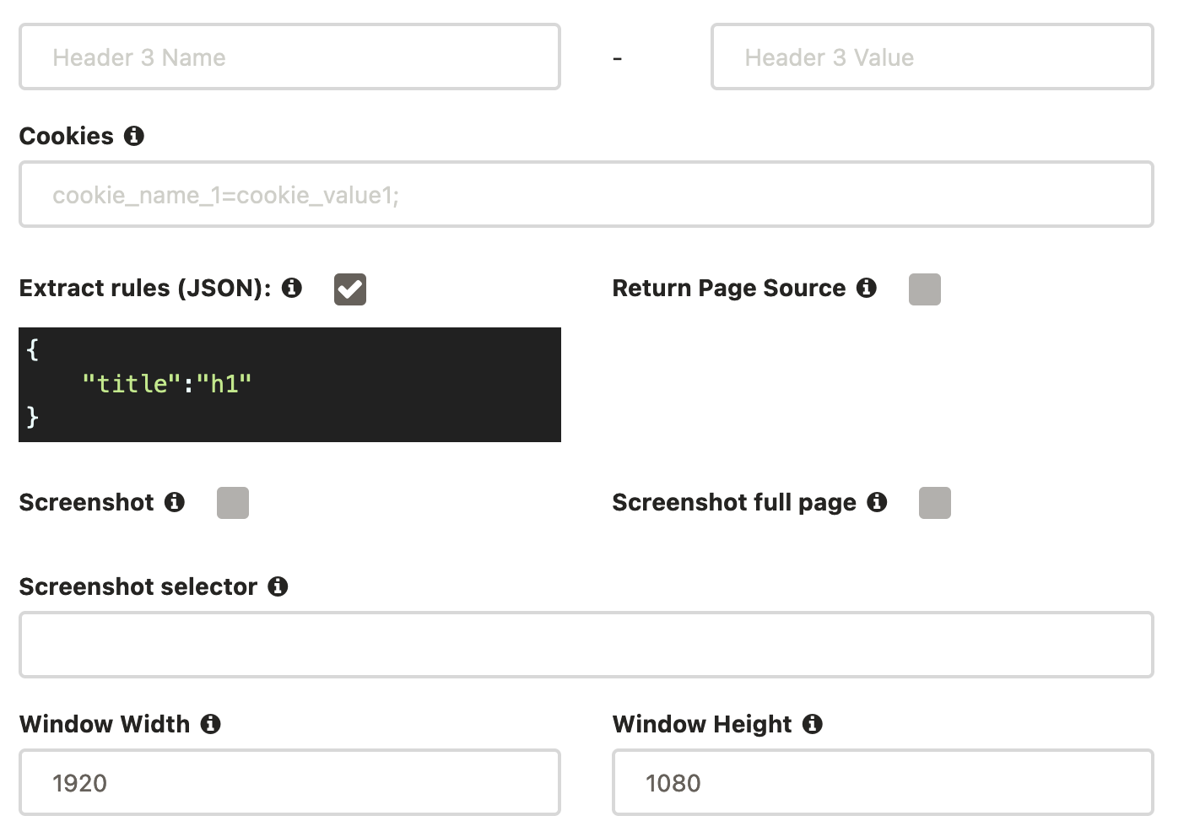
For users who want control, ScrapingBee supports detailed extraction rules using CSS or XPath selectors. You get back a JSON object instead of full HTML. It also supports:
- HTML to PDF conversion
- Screenshots
- Custom user agents and cookies
- Persistent sessions (5 minutes)
Python and Node.js SDKs + No-Code Integration

ScrapingBee provides SDKs for Python and Node.js. There’s also support for no-code tools like Make.com. The web dashboard includes a test console and logs to help troubleshoot scraping jobs.
ScrapingBee Pricing Explained
ScrapingBee uses a credit system. You’re charged per request based on the options you enable.
| Feature | Credits per request |
| Proxy without JS | 1 |
| Proxy with JS (default) | 5 |
| Premium Proxy without JS | 10 |
| Premium Proxy with JS | 25 |
| Stealth Proxy with JS | 75 |
Pricing Plans
| Plan | Price | Credits | Concurrency |
| Discovery | $49 | 150,000 | 5 |
| Pro | $99 | 1,000,000 | 50 |
| Startup | $249 | 3,000,000 | 100 |
| Enterprise | $599 | 8,000,000 | 200 |
There’s a free tier with 1,000 credits. Credits don’t carry over, and blocked requests may still be charged depending on how the site responds.
How ScrapingBee Credits Work
Each API call consumes credits based on the complexity of the request. This can be managed by adjusting the proxy type, turning off JavaScript rendering, or skipping premium features when not needed.
Credits are only charged on HTTP status codes like 200 or 404. You won’t be charged for timeouts or certain types of errors, but it’s worth testing specific scenarios.
ScrapingBee API Test: Scraping Amazon Product Data
Amazon is hard to scrape due to aggressive bot protection. Using ScrapingBee’s default settings, you can extract product titles, prices, and links with about 5 credits per request. No blocks were reported during tests using default proxies.
If you add Premium Proxy, stability improves further, but costs increase to 25 credits per request. The tradeoff between reliability and cost is clear.
ScrapingBee Benchmarks vs Scrapfly, WebScrapingAPI, and Others
Benchmarks from Scrapeway (July 2025) show ScrapingBee delivers fast responses but lower success rates than some competitors.
| Tool | Success Rate | Speed | Cost per 1k |
| Scrapfly | 96% | 13.0s | $4.89 |
| WebScrapingAPI | 92% | 16.8s | $2.71 |
| ScrapingBee | 52% | 4.1s | $3.12 |
| ScraperAPI | 63% | 11.4s | $4.72 |
ScrapingBee performs well on sites like Amazon, Instagram, and Booking.com, where success rates were over 90%. It struggles more with complex targets like LinkedIn or Zillow.
ScrapingBee Pros and Cons
Like any tool, ScrapingBee has its strengths and trade-offs:
What Works
- Fast setup for scraping dynamic pages
- No need to manage proxies or browsers
- AI scraper saves time on layout-specific work
- Clear docs, test tools, and developer SDKs
What’s Missing
- Credits may be charged for failed requests
- Lowest plan isn’t cost-efficient
- No built-in workflow management or scheduling
- Doesn’t support every scraping target well
Best Use Cases for ScrapingBee
ScrapingBee is a good fit for projects like:
- Extracting product data from online stores
- Scraping job boards and real estate listings
- Running lightweight data pipelines
- Testing AI extraction models
- Web scraping without building your own proxy system
When ScrapingBee Might Not Be the Right Tool
ScrapingBee may not be the best choice if you:
- Need a full scraping workflow manager or scheduler
- Require 95%+ success rate across all targets
- Have strict budget limits and can’t optimize credits
- Need a UI for team collaboration or large-scale orchestration
Alternatives worth considering:
- Apify for full-stack scraping flows
Scrapfly for better anti-bot performance - WebScrapingAPI for budget-friendly scraping at scale
How to Start Using ScrapingBee for Free
- Go to scrapingbee.com
- Create a free account (1,000 credits included)
- Use the Python or Node SDK to test
- Check logs and tune your settings based on the response
Final Verdict
ScrapingBee is a solid choice for developers and teams that need a web scraping API to handle headless browsers, rotate proxies, and pull data from JavaScript-heavy sites. It’s easy to implement, fast, and flexible—whether you need raw HTML, structured JSON, or AI-driven extraction.
It may not be the best fit for complex workflows or scraping highly protected sites, but for most mid-size use cases like price monitoring, listings, or product data, it offers a good balance of simplicity and control. Free credits make it easy to test before scaling.










